So now you have the budget for buying nice tools and hiring bright minds. Getting Splunk deployed and data flowing in will soon be past. What’s next then? How to benefit from this investment? Enter Use Cases Development.
It takes a great deal of time until a use case can be fully leveraged. But before you say Machine Learning is the answer, stick to the basics and you can quickly realize there will be enough on your plate to work on for the next year or so.
Think about low hanging fruits, quick wins or whatever you wanna call the intersection between value and feasibility. This is the way to go, especially if you are just starting in this endeavor.
Once there’s an agreement about the initial use cases, whether it’s a correlation search or an interactive dashboard, you should start treating these and other knowledge objects as code. Just like any other system with input (logs), process (rule/dashboard) and output (alert/insight).
Having a well defined set of initial use cases seems obvious but it is far from being reality in most organizations. Quite the opposite, I’ve seen lots of SIEM or Big Data projects with no clear targets (goal).
There are many software development methodologies, most falling into a more general concept called SDLC – systems development life cycle. Without getting into the system/software discussion, here’s Wikipedia’s definition for it:
The SDLC is a term used in systems engineering, information systems and software engineering to describe a process for planning, creating, testing, and deploying an information system.
The process (cycle) is represented by the following chart:
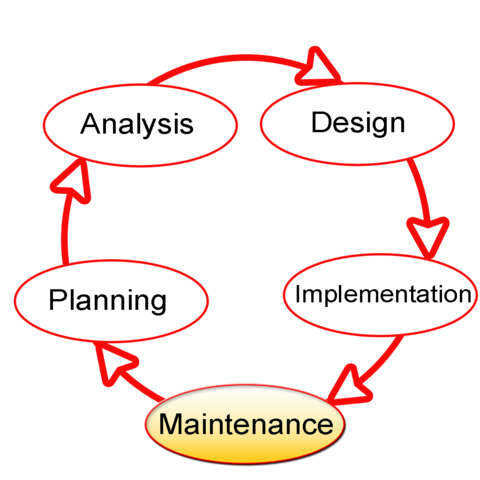
Can you already spot similarities with SIEM use cases development process here?
The stages can be expanded into multiple smaller boxes, of course. This concept evolved and now there are many approaches applied to software development process, with a wide range of methodologies and frameworks.
Below are three basic approaches applied to software development methodology frameworks, perhaps even easier to compare to what security engineers are trying to achieve with development of good detection rules or threat hunting exercises.
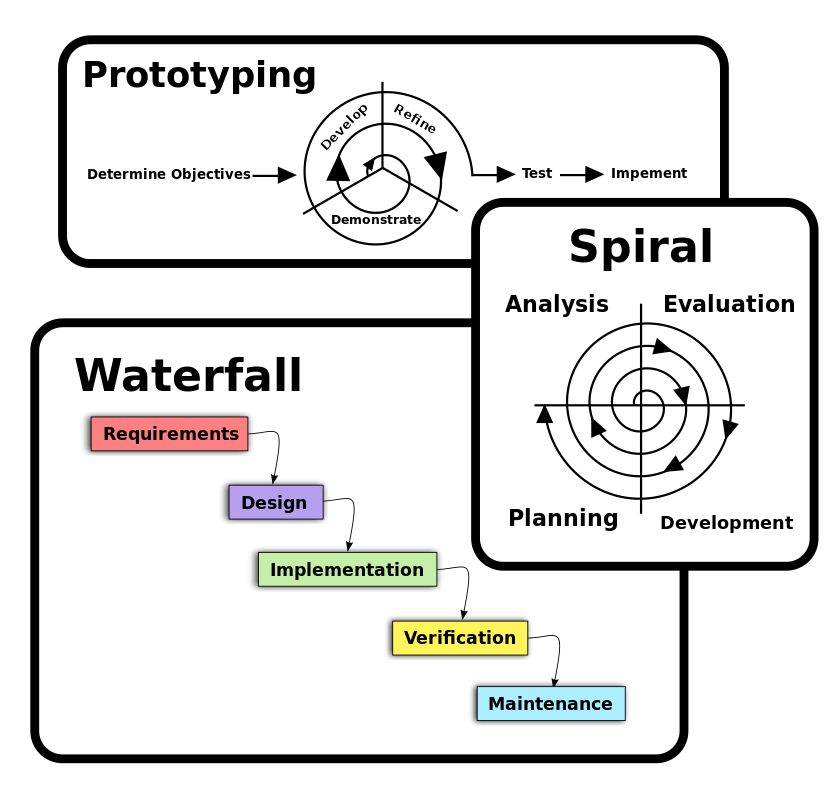
So why not following a standard process for implementing use cases as well? For instance, why not improving the quality of a rule before flagging it as ready?
Before the analysts start triaging poor alerts, there are many obvious sanitization steps to be done, like getting rid of obvious exceptions or enriching the alerts with data already available at your indexers (anticipation).
A few mature teams are already standardizing and streamlining this process. The better they get at doing that, the more the need for prioritization of new ideas (demand).
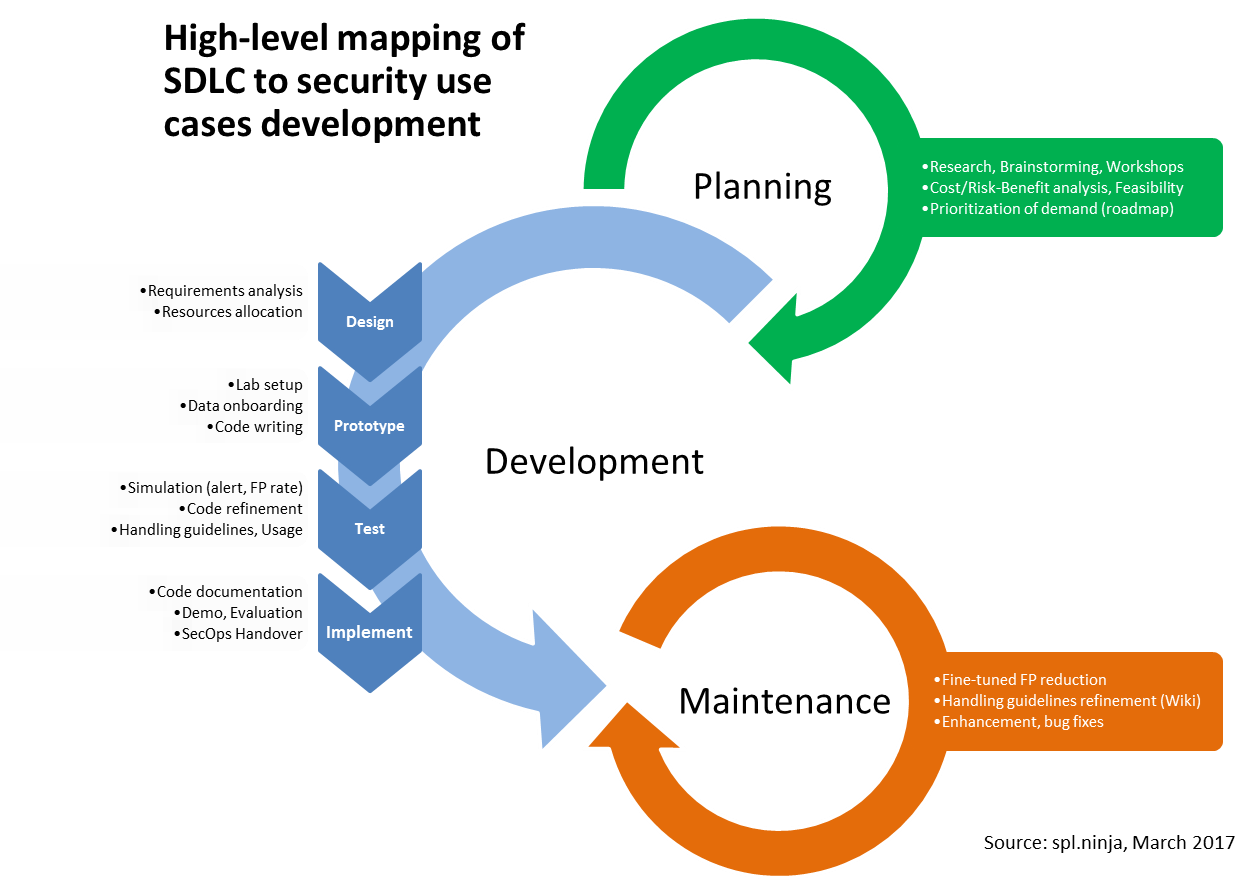
Below is my attempt to summarize that on a chart, still very high-level but it should provide and idea on how to go forward. Feel free to reach out in case you are interested in bouncing ideas around that since I’ve been implementing that in the field.
Update: If you got this far, here is a JIRA Workflow that I have evolved over time reflecting upon the ideas from this post.
